Compaction Techniques & Crash Recovery in HBase
Compaction in HBase
- The recommended maximum region size is 10 - 20 Gb. For HBase clusters running version 0.90. x, the maximum recommended region size is 4 Gb and the default is 256 Mb.
- Compaction in HBase is a process by which HBase cleans itself.
- HBase is a distributed data store optimized for read performance. Optimal read performance comes from having one file per column family. It is not always possible to have one file per column family during the heavy writes. That is reason why HBase tries to combine all HFiles into a large single HFile to reduce the maximum number of disk seeks needed for read. This process is known as compaction.
- Compactions can cause HBase to block writes to prevent JVM heap exhaustion.
- Whereas this process is of two types:
- Minor HBase Compaction
- Major HBase Compaction.
- This Minor and Major Compaction will take time for merging/zipping those files so it makes network traffic. For avoiding network traffic, it is generally scheduled during low peak load timings.
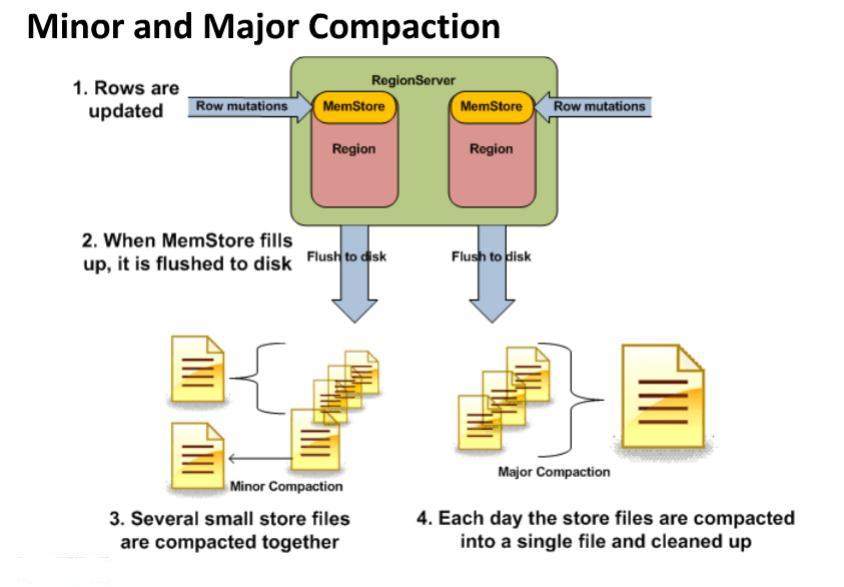
HBase Minor Compaction
- The process of combining the configurable number of smaller HFiles into one large HFile is what we call Minor compaction.
- This helps to eliminate the storage limitations.
- When MemStore fills then it automatically takes all the files and compact/zip together then move it to disk.
- Though, it is quite important since, reading particular rows needs many disk reads and may reduce overall performance, without it.
- One can manually trigger the minor compaction using below command,
- minor_compact "table name"
- Here are the several processes which involve in HBase Minor Compaction, are:
- By combining smaller Hfiles, it creates bigger Hfile.
- Also, Hfile stores the deleted file along with it.
- To store more data increases space in memory.
- Uses merge sorting.
HBase Major compaction
- Whereas, a process of combining the StoreFiles (HFiles) of regions into a single StoreFile, is what we call HBase Major Compaction. Also, it deletes remove and expired versions. As a process, it merges all StoreFiles into single StoreFile and also runs every 24 hours.
- However, the region will split into new regions after compaction, if the new larger StoreFile is greater than a certain size (defined by property).
- It increases read performance. Major compaction is not designed to run very often.
- By default, major compactions run every 24 hours and merge together all store files into one. After a major compaction runs, there is a single StoreFile for each store.
- Due to major compaction rewrites all of the files, lots of disk I/O and network traffic might occur during the process. Major compaction are usually scheduled for weekends or evenings.
- One can manually trigger the major compaction using below command,
- major_compact "table name"
- Well, the HBase Major Compaction in HBase is the other way to go around:
- Major compaction is a heavyweight operation, so run it when your cluster load is low.
- Major compaction is not just about compacting the files. When the record is deleted or version is expired, you need to perform all that cleanup. Major compaction will help us in cleaning up the records.
- Whenever you runs Major Compaction, please make sure you use "hbase.hregion.majorcompaction.jitter" to ensure the major compaction doesn't run on all the nodes at the same time.
- Possibilities for traffic congestion.
- All deleted files or expired cells are deleted permanently, during this process.
- Data present per column family in one region is accumulated to 1 Hfile.
Difference between both compaction
- If all the files need to be merged, then we can run a major compaction which will do the same thing as the minor one, but with the bonus of deleting the required marked cells.
- major compaction brings back data locality of HBase(when it is used over HDFS). minor compaction cannot restore data locality.
- major compaction does almost the same thing like minor compaction except handling deleted rows.
HBase Minor Compaction leads to two outcomes:
As the files being touched are relatively newer and smaller, the capability to impact data locality is very low. In fact, during a write operation, a region server tries to write the primary replica of data on the local HDFS data node anyway. So, a minor compaction usually does not add much value to data locality.
Since the delete markers are not removed, some performance is still left on the table. That said, minor compactions are critical for HBase read performance as they keep the total file count under control which could be a big performance bottleneck especially on spinning disks if left unchecked.
HBase Major Compaction also leads to two outcomes:
Since delete markers and deleted data is physically removed, file sizes are reduced dramatically, especially in a system receiving a lot of delete operations. This can lead to a dramatic increase in performance in a delete-heavy environment.
Since all data of a store is being rewritten, it's a chance to restore the data locality for older (and larger) files also where the drift might have happened due to restarts and rebalances as explained earlier. This leads to better IO performance during reads.
Data Locality
Data sets in Hadoop is stored in HDFS. It is divided into blocks and stored across the data nodes in a Hadoop cluster. When a MapReduce job is executed against the dataset, the individual Mappers will process the blocks (input splits). When data is not available for Mapper in the same node, then data has to copied over the network from the data node that has data to the data node that is executing the Mapper task. This is known as a data locality.
Data locality in Hadoop is divided into three categories.
1. Data Local Data Locality
When data is located on the same node as the mapper working on the data, it is referred as data local data locality. In this case, the proximity of data is very near to computation. This is the most preferred scenario.
2. Intra-Rack Data Locality
It is always not possible to execute the Mapper on the same node as data due to resource constraints. In such cases, the Mapper is executed on another node within the same rack as the node that has data. It is referred as intra-rack data locality.
3. Inter-Rack Data Locality
It is always not possible to achieve data locality as well as intra-rack locality due to resource constraints. In such cases, we will execute the mapper on nodes on different racks, and the data is copied from the node that has data to the node executing mapper between racks. It is referred as inter-rack data locality. This is the least preferred scenario.
HBase Crash and Data Recovery

- Whenever a Region Server fails, ZooKeeper notifies to the HMaster about the failure.
- Then HMaster allocates the regions, WAL of crashed Region Server to many active Region Servers to recover the data of the MemStore.
- Each Region Server re-executes the WAL to build the MemStore for that failed region's column family.
- The data is written in chronological order (in a timely order) in WAL. So if we re-executed the WAL then it will be ease for recover and store the data in MemStore file.


Comments
Post a Comment