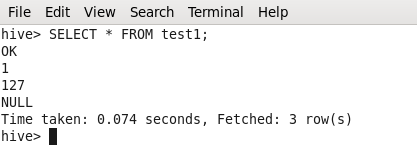
Spark Architecture

Apache Spark is an open-source distributed computing system that provides an interface for programming entire clusters with implicit data parallelism and fault tolerance. It's designed to handle large-scale data processing and analytics tasks efficiently. Spark's architecture is structured to maximize performance and scalability. Architecture Driver Program The driver program is the entry point of any Spark application. The driver program is responsible for translating the user's code into tasks and distributing them to the executors. The Driver Program is a process that runs the main() function of the application and creates the SparkContext object which represents the connection to the Spark cluster. When a user submits a Spark application, the Driver Program receives the application code and any associated configurations. Rest of the technical stuffs could be taken by SparkContext. The Driver Program interacts with the cluster manager (such as Apache Mesos or Y...